A friend recently requested some less LLM-centric content. I’ve often said this blog is largely a lab notebook for various ideas or build log. It’s also merely a subset of the stuff swirling around in my brain than a dedication to any one topic. In any case, this post is dedicated to Pete.
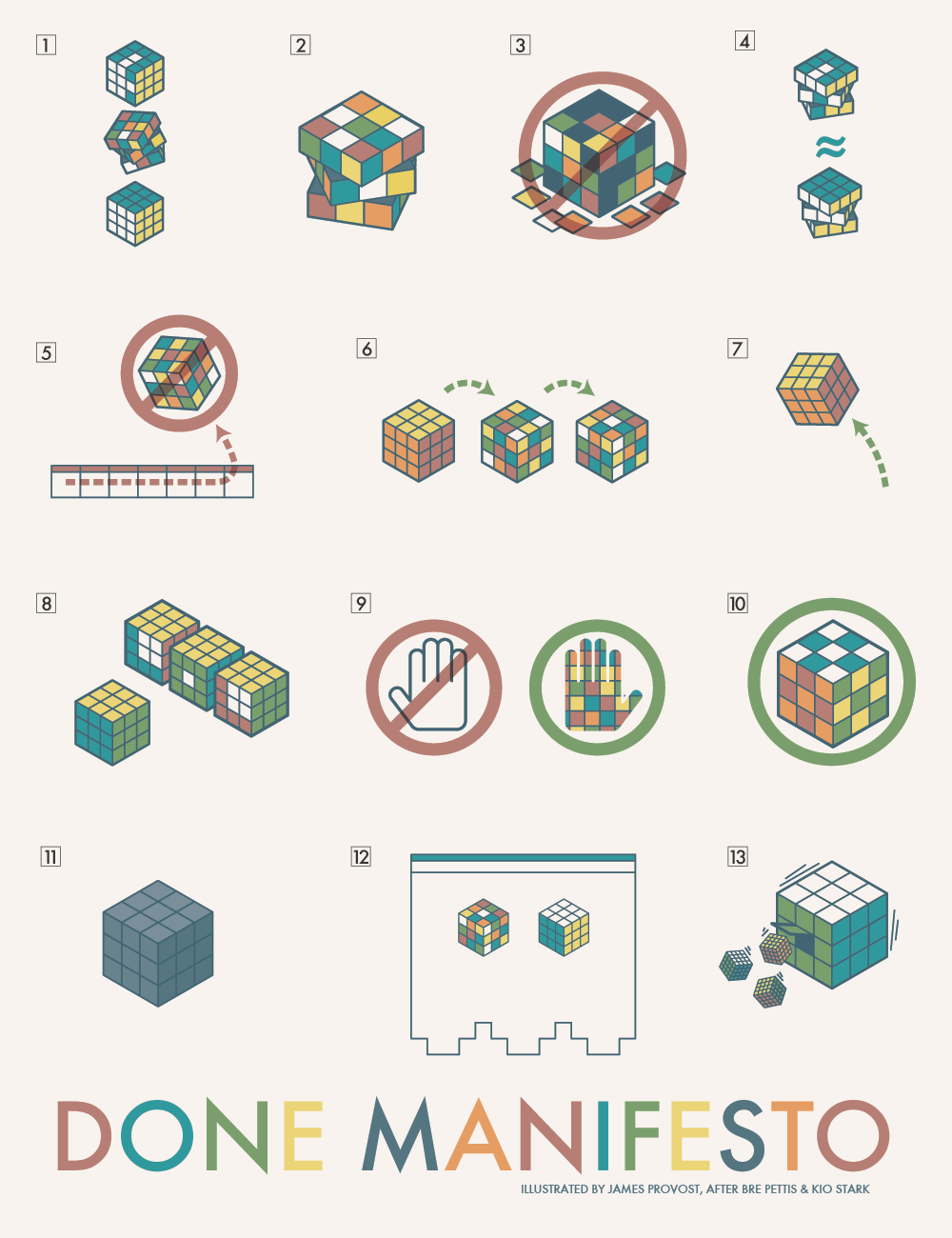
I saw the above 3D printed box on Instagram. It looks like a wanted poster from the show “One Piece” of a character named Roronoa Zoro who carries three swords. The box contains a small post in the very center which seems very out of place – until the lights are dimmed and the light under the tip of the post is activated, revealing the light is blocked by the irregular edges of the box and casts a shadow of the silhouette of a figure holding three swords.
I’ve seen other implementations of this stereographic projection technique, but this was easily the coolest. The disparity between the size and shape of the box and shadow was almost startling.
My mind went wild with ideas upon seeing this box. One of the first ideas I had related to some fan-made movie posters by Kevin Collert many years ago.1 Imagine a small projector / box of arbitrary shape that could project that kind of silhouette behind you?
Yeah, a Tony Stark cosplay is neat… but what if you had an inconspicuous stereographic projector on your back that threw up a huge Iron Man shadow behind you!?
This could be extended in any number of ways. A Luke Skywalker cosplay that casts a Darth Vader shadow, Bruce Banner with a Hulk, etc, etc. But, also, what about a shadow of a familiar? A little dragon perched behind you. Or two thugs standing to your side like evil shadow henchmen? Or a crowd of zombies? The neat part about the box / lamp shown on Instagram was that the box didn’t look like it would display that kind shadow of a shadow. It just looked like a box with weird edges to it.
But, how did they do it?

I’m terrible at Blender. I’ve watched tutorials, tried to use it, but I just can’t wrap my feeble mind around it. My one string is the ability to make things in OpenSCAD. There are plenty of others who can make incredible things in it, but I’m no slouch. The code may not be pretty, but, well, as they say…

I started with a few assumptions.
- The light source has to be a single point. If there were multiple LED’s or filaments, it would create fuzzy / duplicate shadow edges. This should be possible with a single bright LED.
- The shadow is basically a cone. The edge of the shadow everywhere must be essentially some sort of a distorted cone, with the center point being the single point of light and the edges of the silhouette being the edge of the cone.
- The top edge of the box must be where the cone intersects with the box. If we decide how far off the wall the point of light is and we know where we want the shadow to be and where the shadow edges are, we should be able to intersect the shadow-cone with a thin walled box.
Creating the box itself shouldn’t be that big a deal. It’s an easy few lines of OpenSCAD. Creating the arbitrary “cone” was initially a much harder problem. Now, if the design I was trying to create was very simple or entirely convex, I could just use the OpenSCAD hull function around an SVG of the desired shadow and a very small sphere for the point of light. Since a simple shape would be uninteresting, I knew that hull wasn’t going to work. For a while I tried really hard to build a python program that would work by creating a polyhedron built out of the large SVG in the desired location and a very small SVG at the light point – and stitching the sides together programmatically. If you’ve ever worked with the OpenSCAD polyhedron functions, you know what a pain it is. If you don’t define the faces in a certain order or order the faces properly, you’ll end up with flipped faces and a pile of useless triangles. Even when the faces were properly built, the result ended up being difficult for OpenSCAD to render since it involved so many points converging on so few points and weird little overlaps. It was a mess.

You mean, all I have to do is RFTM? Apparently the linear_extrude function has a parameter called “scale” where you can define how small something should get as it is extruded. This is literally exactly what I needed.
I needed the shadow on the wall to be extruded off the wall as high as the point of light, but scaled down to that same point of light. But, would this work??? I haven’t printed it yet, but I believe it should.
From there, the next question is… does this OpenSCAD back-of-the-napkin sketch really work? Again, I’m not sure – I haven’t printed this for a few different reasons. If this design were printed “as is”, there would be a ton of overhangs and support material. I believe when you look at some of the pictures of the lamp lit up from the side, you can see the infill patterns on the sides. I can’t tell from these videos – but I suspect the easiest way to 3D print this box would be to do so in big flat panels. At the point you’re just trying to turn filament into 2D panels, why even bother printing it when you could lasercut it in a fraction of the time?
Let’s look at a few stills of the lamp.
Now, for my quick mockup I just used a simple square shape – but you can definitely see the same features as in the lamp in the video stills. The head, the crossed sword tips at the left, the jagged edges on the bottom right, the floating sword on the right.
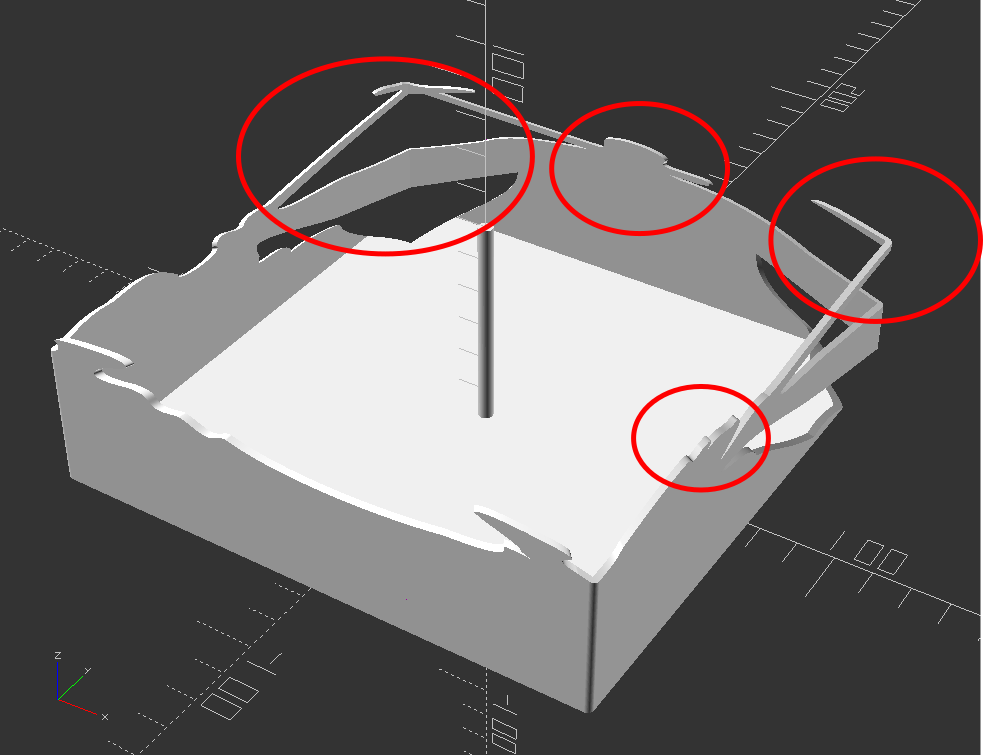
Given that the theory feels intuitive and sound and that my quick mockup proof of concept seems to have the same structural features as the lamp in the video… this seems like it would work.
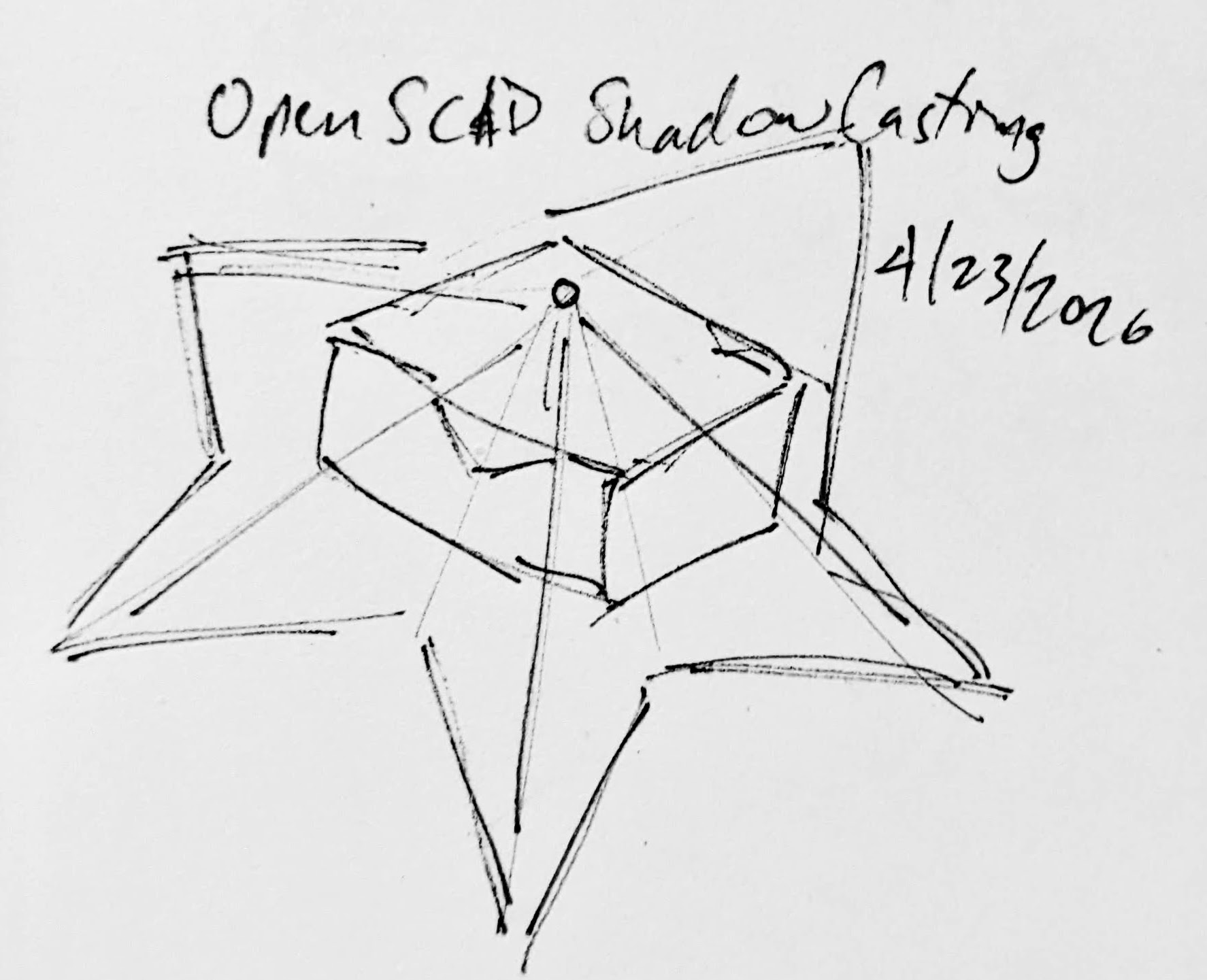
If this quick mockup works, then why restrict ourselves to simple boxes? For a mass produced thing you just want to stamp out, a simple box just makes sense. You could lasercut the panels, slap them together, and churn them out all day long. But, the thing that you use to block the light and form the shadow could be any arbitrary shape. It could be a triangle, star, or something far more complex. Here’s another quick sketch:
Obviously, this would be a support structure nightmare. But, for a one-off project and a cool enough idea, I think it could definitely work!
- His work has been stolen and slapped on so many dropshipped things that it was very difficult to find the original artist! [↩]